11.1. Теория¶
Стандартная библиотека Python включает множество пакетов и модулей, предоставляющих дополнительную функциональность для выполнения различных задач.
Примечание
В раздел также включены функции, модули и пакеты, не относящиеся напрямую к стандартной библиотеке (например, math или pytz).
Содержание
11.1.1. Математика¶
11.1.1.1. Модуль math¶
Модуль math предоставляет доступ к математическим функциям, определяемым стандартом языка Си. Как правило, все функции модуля math возвращают значения вещественного типа.
Константы
-
math.pi¶ Константа \(\pi = 3.141592...\), с доступной точностью.
-
math.e¶ Константа \(e = 2.718281...\), с доступной точностью.
Округление чисел
-
math.ceil(x)¶ Возвращает наименьшее целое, большее или равное вещественному
x.
-
math.floor(x)¶ Возвращает наибольшее целое, меньшее или равное вещественного
x.
-
math.trunc(x)¶ Возвращает целую часть
xв виде целого числа.
-
math.isclose(a, b, *, rel_tol=1e-09, abs_tol=0.0)¶ Возвращает
Trueесли значенияaиbравны с заданной точностью.- Параметры
rel_tol – относительная погрешность: максимально допустимая разница между
aиbотносительно максимального значения их модулей; задается в процентах, например, для погрешности в 5%rel_tol=0.05;abs_tol – абсолютная погрешность: минимально допустимая разница между
aиb; как правило, используется для сравнения с нулевым значением.
Результат функции эквивалентен:
abs(a-b) <= max(rel_tol * max(abs(a), abs(b)), abs_tol)Пример:
>>> math.isclose(5.0012, 5.001, rel_tol=0.001) # 0.0002 < 0.0050012, до 3-х знаков True
Степень и логарифмы
-
math.exp(x)¶ Возвращает \(e^x\).
-
math.factorial(x)¶ Возвращает факториал
x.
-
math.log(x[, base])¶ Возвращает логарифм числа
xпо основаниюbase(\(e\) по умолчанию).
-
math.log2(x)¶ Возвращает логарифм числа
xпо основанию 2.
-
math.pow(x, y)¶ Возвращает \(x^y\).
Эквивалентно
x**y, но принудительно конвертирует аргументы в типfloat.
-
math.sqrt(x)¶ Возвращает квадратный корень из
x.
Изменение знака
-
math.fabs(x)¶ Возвращает
|x|. В отличие отabs()принудительно переводит аргумент в типfloat.
-
math.copysign(x, y)¶ Возвращает
xсо знакомy.
Тригонометрические функции
-
math.sin(x)¶ -
math.cos(x)¶ -
math.tan(x)¶ Возвращает значение тригонометрических функций (синус, косинус, тангенс).
- Параметры
x – угол в радианах.
-
math.asin(x)¶ -
math.acos(x)¶ -
math.atan(x)¶ Возвращает значение обратных тригонометрических функций (арксинус, арккосинус, арктангенс).
- Параметры
x – значение соответствующей функции.
- Результат
угол в радианах
-
math.hypot(x, y)¶ Возвращает «гипотенузу», эквивалентно
sqrt(x*x + y*y).
-
math.degrees(x)¶ Возвращает значение
xрадиан в градусах.
-
math.radians(x)¶ Возвращает значение
xградусов в радианах.
Пример использования модуля приведен в Листинге 11.1.1.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | import math
# Гипотенуза прямоугольного треугольника с катетами a и b
a, b = 4, 3
print(math.hypot(a, b)) # 5.0
print(math.sqrt(a**2 + b**2)) # 5.0
print((a**2 + b**2)**0.5) # 5.0
# Площадь круга
r = 1
print(math.pi * r**2) # 3.141592653589793
# Вычисление площади треугольника по сторонам и углу между ними
a, b, alpha = 3, 4, 90
print(a * b * math.sin(math.radians(alpha))) # 5.0
# Округление чисел
print(round(-4/3, 2), round(4/3, 2)) # -1.33, 1.33
print(round(-4/3), round(4/3)) # -1, 1
print(int(-4/3), int(4/3)) # -1, 1
print(math.ceil(-4/3), math.ceil(4/3)) # -1, 2
print(math.floor(-4/3), math.floor(4/3)) # -2, 1
print(math.trunc(-4/3), math.trunc(4/3)) # -1, 1
print(math.isclose(1/3, 0.333, abs_tol=0.001)) # True
print(math.isclose(1/3, 0.333, abs_tol=0.0001)) # False
# Степень и логарифмы
print(math.log(math.exp(2))) # 2.0
print(math.factorial(5)) # 120
|
11.1.1.2. Модуль random¶
Модуль random реализует генератор псевдослучайных чисел (ГПСЧ).
Случайность - проблема для компьютерной техники, поскольку все компьютеры являются цифровыми, и как следствие, детерминированы. Если дать компьютеру одни и те же инструкции, будет получаться один и тот же результат. Получается, что математически невозможно сгенерировать по-настоящему случайные числа, используя компьютер, однако довольно просто сгенерировать псевдослучайные числа. В отличие от случайных чисел одни и те же псевдослучайные могут быть сгенерированы раз за разом.
Псевдослучайные числа обладают определенными характеристиками:
сгенерированная последовательность не должна повторяться;
числа в последовательности должны быть равномерно распределены на определенном промежутке.
Примеры последовательностей:
плохие последовательности:
3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3(все числа одинаковы);0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9(отсутствует случайность);1 3 2 5 3 9 1 2 4 2 5 1 1 2 8 1 5 2 3 4(неравномерно распределена);2 8 4 6 0 9 8 2 4 8 6 4 2 2 5 1 4 8 6 2(много четных чисел);
хорошие последовательности:
6 9 1 2 0 4 2 8 5 7 2 9 1 9 2 5 3 1 9 2;6 2 5 3 4 1 9 7 8 0 2 1 6 4 5 8 9 5 0 9;1 8 5 2 3 4 5 7 9 5 2 1 0 2 1 0 9 7 6 4;9 0 6 4 8 3 1 5 2 7 6 1 4 6 0 1 9 7 5 6.
Для инициализации ГПСЧ требует определенное целое число (т.н. инициализатор), определяющее будущую генерируемую последовательность. При этом в целом нет возможности узнать зависимость между этим числом и получаемой последовательностью.
Практически все функции модуля основаны на функции random(). Для генерации чисел используется алгоритм «Вихрь Мерсенна», который лишен многих недостатков, присущих другим алгоритмам генерации (малый период, предсказуемость, легко выявляемая статистическая зависимость и др.). При этом данный алгоритм не является криптостойким (в данном случае, теоретически возможно «предсказать» их генерацию), поэтому не должен использоваться для задач, связанных с информационной безопасностью (например, для криптографии, шифрования и т.д.).
Общие функции
-
random.seed(a=None, version=2)¶ Инициализирует генератор.
Если аргумент
aпередан, используется в качестве инициализатора, в противном случае используется системное время.
-
random.getrandbits(k)¶ Возвращает целое число из
kслучайных бит.Например, если
k = 4, сгенерируется случайное двоичное число от \({0000_{2}}\) до \({1111_{2}}\) (от \({0_{10}}\) до \({15_{10}}\) соответственно).
Целые числа
-
random.randrange(stop)¶ -
random.randrange(start, stop[, step]) Возвращает случайное число из полуинтервала
[start; stop)с шагомstep.Параметры аналогичны функции range().
-
random.randint(a, b)¶ Возвращает случайное число на отрезке \([a; b]\).
Эквивалентно
randrange(a, b + 1).
Вещественные числа
-
random.random()¶ Возвращает случайное число из полуинтервала \([0.0; 1.0)\).
-
random.uniform(a, b)¶ Возвращает случайное число на отрезке \([a; b]\).
Эквивалентно
a + (b-a) * random().
Последовательности
-
random.choice(seq)¶ Возвращает случайный элемент из последовательности
seq.Если в
seqнет элементов, возбуждается исключениеIndexError.
-
random.shuffle(x[, random])¶ Перемешивает последовательность
x.
-
random.sample(population, k)¶ Возвращает список неповторяющихся элементов длины
k, выбранных из последовательностиpopulation(«случайная выборка без возврата»).Если
k > len(population), возбуждается исключениеValueError.
Распределение случайных величин
-
random.gauss(mu, sigma)¶ -
random.normalvariate(mu, sigma)¶ Возвращает число, полученное по закону нормального распределения (распределение Гаусса).
- Параметры
mu – среднее значение;
sigma – стандартное отклонение.
Первая функция не потокобезопасна, но работает несколько быстрее.
Пример использования модуля приведен в Листинге 11.1.2.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | import random
random.seed(100)
# Случайное число от 1 до 10
print(random.randint(1, 10)) # 3
# Случайное нечетное число от 1 до 10
print(random.randrange(1, 11, 2)) # 7
# Случайное вещественное число от 0 до 1
print(random.random()) # 0.45492700451402135
# Случайное вещественное число от -10 до 10
print(random.uniform(-10, 10)) # 5.415676113180442
# Список из 5 случайных целых чисел [1, 100]
A = [random.randint(1, 100) for i in range(5)]
print(A) # [91, 51, 94, 45, 56]
# Список из 10 неповторяющихся целых чисел из отрезка [0, 99]
A = random.sample(range(100), 10)
print(A) # [33, 6, 84, 82, 26, 42, 29, 39, 98, 22]
# Случайный элемент из последовательности
nums_0_to_5 = list(range(5))
print(random.choice(nums_0_to_5)) # 4
# Перемешиваем список
random.shuffle(nums_0_to_5)
print(nums_0_to_5) # [2, 1, 3, 4, 0]
|
11.1.1.3. Модуль statistics¶
Модуль statistics содержит функции для осуществления статистических операций. Как правило, все функции поддерживают целые и вещественные типы.
Показатели центра распределения
-
statistics.mean(data)¶ Возвращает среднее арифметическое элементов
data(последовательности или итерируемого объекта).Если
len(data) == 0, возбуждается исключение StatisticsError.
-
statistics.median(data)¶ Возвращает медиану последовательности
data.Если
len(data) == 0, возбуждается исключение StatisticsError.
-
statistics.mode(data)¶ Возвращает моду последовательности
data.Если
len(data) == 0или все элементыdataуникальны, возбуждается исключение StatisticsError.
Показатели разброса
-
statistics.variance(data, xbar=None)¶ -
statistics.pvariance(data, mu=None)¶ Возвращает дисперсию для выборки или генеральной совокупности соответственно.
Последовательность
dataдолжна содержать по крайней мере 2 значения, иначе возбуждается исключениеStatisticsError.xbarиmu- средние значения, если равныNone, вычисляются автоматически.
-
statistics.stdev(data, xbar=None)¶ -
statistics.pstdev(data, mu=None)¶ Возвращает стандартное отклонение (квадратный корень из дисперсии) для выборки или генеральной совокупности соответственно.
Последовательность
dataдолжна содержать по крайней мере 2 значения, иначе возбуждается исключениеStatisticsError.xbarиmu- средние значения, если равныNone, вычисляются автоматически.
Пример использования модуля приведен в Листинге 11.1.3.
1 2 3 4 5 6 7 8 9 | import statistics
A = [1, 1, 2, 3, 3, 3, 4, 4, 5, 8, 8, 9]
print(statistics.mean(A)) # 4.25
print(statistics.median(A)) # 3.5
print(statistics.mode(A)) # 3
print(statistics.variance(A)) # 7.4772727272727275
print(statistics.stdev(A)) # 2.7344602259445514
|
11.1.2. Дата/время¶
Python поддерживает работу с датой и временем в объектно-ориентированном стиле и предоставляет соответствующие модули и пакеты (Таблица 11.1.1).
Модуль / Пакет |
Описание |
|---|---|
Классы для работы с датой/временем |
|
Функции для работы с временем |
|
Классы для работы с календарем |
|
Данные о всех временных зонах согласно базе данных часовых поясов |
11.1.2.1. Модуль datetime¶
Ключевым модулем для работы с датой/временем является модуль datetime (Таблица 11.1.2).
Класс |
Описание |
|---|---|
Время, не привязанное к конкретному дню (считает, что каждый день содержит 24*60*60 секунд) |
|
Дата по Григорианскому календарю |
|
Комбинация |
|
Интервал между двумя |
|
Абстрактный класс-информация о временной зоне. Используется классами |
|
Класс-потомок |
Все экземпляры данных классов являются немутирующими (неизменяемыми).
Классы time или datetime могут быть «наивными» или «осведомленными»:
«наивный» (англ. Naive) или «неосведомленный»: не содержит информацию о часовых поясах (временных зонах), летнем/зимнем времени и представляет «чистую» дату/время, которую можно интерпретировать так, как это понадобится в приложении;
«осведомленный» (англ. Aware): знает и содержит информацию о часовых поясах (временных зонах), летнем/зимнем времени, однозначно определяя дату/время.
Naive-вариант проще в использовании и может использоваться в приложении, если нет необходимости учитывать часовые пояса или летнее/зимнее время.
11.1.2.1.1. Константы¶
-
datetime.MINYEAR¶ Наименьший год, который может быть задан для объектов класса
dateилиdatetime.MINYEAR = 1.
-
datetime.MAXYEAR¶ Наибольший год, который может быть задан для объектов класса
dateилиdatetime.MAXYEAR = 9999.
11.1.2.1.2. Класс timedelta¶
Объект timedelta представляет собой интервал между двумя датами (date) или значениями времени (time).
Конструкторы
-
class
datetime.timedelta(days=0, seconds=0, microseconds=0, milliseconds=0, minutes=0, hours=0, weeks=0)¶ Все параметры являются необязательными и могут быть положительными или отрицательными, целыми или вещественными числами.
Класс хранит только значение дней, секунд и микросекунд, прочие значение преобразуются в эти величины.
- Параметры
days – дни,
-999999999 <= days <= 999999999;seconds – секунды,
0 <= seconds < 3600*24;microseconds – микросекунды,
0 <= microseconds < 1000000;milliseconds – миллисекунды;
minutes – минуты;
hours – часы;
weeks – недели.
- Исключение
OverflowError – в случае нарушения допустимых границ значений.
timedelta-объекты также являются хешируемыми и могут сериализоваться через pickle.
Как правило, объекты данного класса создаются не напрямую, а являются результатами разностных операций прочих классов.
Операции
Для объектов класса timedelta доступны следующие операции (Таблица 11.1.3).
Операция (пример) |
Описание |
|---|---|
|
Сумма |
|
Разность |
|
Умножение на целое число |
|
Умножение на вещественное число |
|
Деление |
|
Деление на целое или вещественное число |
|
|
Поля
-
class
datetime.timedelta¶ -
min¶ Минимально допустимая разница,
timedelta(-999999999).
-
max¶ Максимально допустимая разница,
timedelta(days=999999999, hours=23, minutes=59, seconds=59, microseconds=999999).
-
resolution¶ Наименьшая возможная разница между двумя различными
timedelta-объектами (1 мкс.).
-
days¶ Количество дней: значение из диапазона
[-999999999; 999999999].Только для чтения.
-
seconds¶ Количество секунд: значение из диапазона
[0; 86399].Только для чтения.
-
microseconds¶ Количество микросекунд: значение из диапазона
[0; 999999]Только для чтения.
-
Методы
11.1.2.1.3. Класс time¶
Класс time представляет собой время, не привязанное к конкретному дню. Поддерживает временные зоны и переход на летнее/зимнее время.
Конструкторы
-
class
datetime.time(hour=0, minute=0, second=0, microsecond=0, tzinfo=None)¶ - Параметры
hour (int) – часы,
0 <= hour < 24;minute (int) – минуты,
0 <= minute < 60;second (int) – секунды,
0 <= second < 60;microsecond (int) – микросекунды,
0 <= microsecond < 1000000;tzinfo (datetime.tzinfo) – объект - временная зона, летнее/зимнее время;
- Исключение
ValueError – в случае нарушения допустимых границ значений.
Операции
Для объектов класса time доступны следующие операции:
взаимное сравнение (naive- и aware-варианты сравнивать нельзя - приводит к
TypeError);хеширование (можно использовать в качестве ключа в словаре);
преобразование в
bool:timeсчитаетсяTrueтолько в случае, если время, выраженное в минутах за вычетомutcoffset(), не равно 0.
Поля
-
class
datetime.time¶ -
min¶ Минимально допустимое время,
time(0, 0, 0, 0).
-
max¶ Максимально допустимое время,
time(23, 59, 59, 999999).
-
resolution¶ Наименьшая возможная разница между двумя различными
time-объектами (1 мкс.).
-
hour¶ Часы. Значение из диапазона
range(24).Только для чтения.
-
minute¶ Минуты. Значение из диапазона
range(60).Только для чтения.
-
second¶ Секунды. Значение из диапазона
range(60).Только для чтения.
-
microsecond¶ Микросекунды. Значение из диапазона
range(1000000).Только для чтения.
-
tzinfo¶ Объект класса
tzinfo(временная зона). ВозвращаетNone, если не установлен.Объект является «осведомленным», если
tzinfoне являетсяNoneиtzinfo.utcoffset(None)не возвращаетNone.Только для чтения.
-
Методы
-
class
datetime.time¶ -
replace([hour[, minute[, second[, microsecond[, tzinfo]]]]])¶ Возвращает исходное время с измененными значениями указанных атрибутов.
-
isoformat()¶ -
__str__()¶ Возвращает строковое представление времени в стандарте ISO 8601 (
'HH:MM:SS.mmmmmm'или'HH:MM:SS').Если имеется сдвиг
utcoffset(), строка дополняется 6-ти символьным значением сдвига относительно UTC ('HH:MM:SS.mmmmmm+HH:MM'или'HH:MM:SS+HH:MM').
-
strftime(format)¶ -
__format__(format)¶ Возвращает строковое представление времени в заданном формате
format(см. Функции strftime() и strptime()).
-
utcoffset()¶ Если
tzinfoне задано, возвращаетNone, иначеself.tzinfo.utcoffset(None).
-
dst()¶ Если
tzinfoне задано, возвращаетNone, иначеself.tzinfo.dst(None).
-
tzname()¶ Если
tzinfoне задано, возвращаетNone, иначеself.tzinfo.tzname(None).
-
11.1.2.1.4. Класс date¶
Класс date представляет собой дату (год, месяц, день) по «идеализированному» Григорианскому календарю, где первый день обозначен как 1.1.1 и т.д.
Конструкторы
-
class
datetime.date(year, month, day)¶ Все параметры являются обязательными.
Операции
Для объектов класса date доступны следующие операции (Таблица 11.1.4).
Операция (пример) |
Описание |
|---|---|
|
|
|
|
|
Разница между двумя датами (результат типа |
|
|
Поля
-
class
datetime.date¶ -
min¶ Минимально допустимая дата,
date(MINYEAR, 1, 1).
-
max¶ Максимально допустимая дата,
date(MAXYEAR, 12, 31).
-
resolution¶ Наименьшая возможная разница между двумя различными
date-объектами (1 день).
-
year¶ Год. Значение из диапазона
[MINYEAR; MAXYEAR].Только для чтения.
-
month¶ Месяц. Значение из диапазона
[1; 12].Только для чтения.
-
day¶ День. Значение из диапазона
[1; кол-во дней в месяце month].Только для чтения.
-
Методы
-
class
datetime.date¶ -
replace(year, month, day)¶ Возвращает исходную дату с измененными значениями указанных атрибутов.
-
toordinal()¶ Возвращает количество дней в дате по пролептическому (расширенному до момента введения) григорианскому календарю, например,
date(2, 1, 1).toordinal() == 366.
-
weekday()¶ Возвращает номер дня недели (Понедельник - 0, Воскресенье - 6).
-
isoweekday()¶ Возвращает номер дня недели (Понедельник - 1, Воскресенье - 7).
-
isocalendar()¶ Возвращает ISO-календарь: кортеж, (ISO год, ISO номер недели, ISO день недели).
-
isoformat()¶ -
__str__()¶ Возвращает строковое представление даты в формате ISO 8601 (
'YYYY-MM-DD'), например:'2002-12-04'.
-
ctime()¶ Возвращает строковое представление даты, например:
'Wed Dec 4 00:00:00 2002'.
-
strftime(format)¶ -
__format__(format)¶ Возвращает строковое представление даты в заданном формате
format(см. Функции strftime() и strptime()).
-
11.1.2.1.5. Класс datetime¶
Класс datetime - единый тип, хранящий информацию как о дате, так и о времени, сочетающий характеристики классов date и time.
Практически все атрибуты совпадают с аналогичными атрибутами классов date и time.
Конструкторы
-
class
datetime.datetime(year, month, day, hour=0, minute=0, second=0, microsecond=0, tzinfo=None)¶ - Параметры
year (int) – год,
MINYEAR <= year <= MAXYEAR;month (int) – месяц,
1 <= month <= 12;day (int) –
1 <= day <=кол-во дней в месяцеmonth;hour (int) – часы,
0 <= hour < 24;minute (int) – минуты,
0 <= minute < 60;second (int) – секунды,
0 <= second < 60;microsecond (int) – микросекунды,
0 <= microsecond < 1000000;tzinfo (datetime.tzinfo) – объект - временная зона, летнее/зимнее время;
- Исключение
ValueError – в случае нарушения допустимых границ значений.
-
class
datetime.datetime¶ -
classmethod
today()¶ Возвращает текущую дату/время без учета временной зоны (
tzinfo==None), например:2015-09-16 16:52:57.484589.
-
classmethod
now(tz=None)¶ Возвращает текущую дату/время аналогично
datetime.datetime.today(), но может быть точнее.Если задана временная зона
tz, дата/время будет преобразовано учитывая ее.
-
classmethod
utcnow()¶ Возвращает текущую UTC дату и время,
tzinfo = None. Аналогичноdatetime.datetime.now(), но возвращает «неосведомленный» объект.
-
classmethod
fromordinal(ordinal)¶ Возвращает текущу дату и время, соответствующую
ordinalзначению дней в пролептическом григорианском календаре; например:datetime.fromordinal(366) # 0002-01-01 00:00:00; время иtzinfoне устанавливаются.
-
classmethod
combine(date, time)¶ Возвращает
datetime-объект, составленный изdateиtime.
-
strptime(date_string, format)¶ Возвращает
datetime-объект, составленный из строкиdate_stringпо форматуformat(см. Функции strftime() и strptime()).
-
classmethod
Операции
Для объектов класса datetime доступны следующие операции (Таблица 11.1.5).
Операция (пример) |
Описание |
|---|---|
|
|
|
|
|
Разница между двумя объектами дата/время (результат типа |
|
|
|
Всегда |
Поля
-
class
datetime.time¶ -
min¶ Минимально допустимое дата/время,
datetime(MINYEAR, 1, 1, tzinfo=None).
-
max¶ Максимально допустимое дата/время,
datetime(MAXYEAR, 12, 31, 23, 59, 59, 999999, tzinfo=None).
-
resolution¶ Наименьшая возможная разница между двумя различными
datetime-объектами (1 мкс.).
-
year¶ Год. Значение из диапазона
[MINYEAR; MAXYEAR].Только для чтения.
-
month¶ Месяц. Значение из диапазона
[1; 12].Только для чтения.
-
day¶ День. Значение из диапазона
[1; кол-во дней в месяце month].Только для чтения.
-
hour¶ Часы. Значение из диапазона
range(24).Только для чтения.
-
minute¶ Минуты. Значение из диапазона
range(60).Только для чтения.
-
second¶ Секунды. Значение из диапазона
range(60).Только для чтения.
-
microsecond¶ Микросекунды. Значение из диапазона
range(1000000).Только для чтения.
-
tzinfo¶ Объект класса
tzinfo. ВозвращаетNone, если не установлен.Объект является «осведомленным», если
tzinfoне являетсяNoneиtzinfo.utcoffset(None)не возвращаетNone.Только для чтения.
-
Методы
-
class
datetime.datetime¶ -
date()¶ Возвращает только дату (
date) изdatetime.
-
time()¶ -
timetz()¶ Возвращает только время (
time) изdatetime.timetz()в отличие отtime()возвращает «осведомленный» объект.
-
replace([year[, month[, day[, hour[, minute[, second[, microsecond[, tzinfo]]]]]]]])¶ Возвращает исходные дату/время с измененными значениями указанных атрибутов.
-
astimezone(tz=None)¶ Возвращает исходные дату/время в соответствии с временной зоной
tz; еслиtz == None, используются системные настройки.
-
utcoffset()¶ Если
tzinfoNone, возвращаетNone, в противном случае:self.tzinfo.utcoffset(self).
-
dst()¶ Если
tzinfoNone, возвращаетNone, в противном случае:self.tzinfo.dst(self).
-
tzname()¶ Если
tzinfoNone, возвращаетNone, в противном случае:self.tzinfo.tzname(self).
-
toordinal()¶ Возвращает номер дня по пролептическому григорианскому календарю.
-
weekday()¶ Возвращает номер дня недели (Понедельник - 0, Воскресенье - 6).
-
isoweekday()¶ Возвращает номер дня недели (Понедельник - 1, Воскресенье - 7).
-
isocalendar()¶ Возвращает ISO-календарь: кортеж, (ISO год, ISO номер недели, ISO день недели).
-
isoformat(sep='T')¶ Возвращает строковое представление даты в формате ISO,
'YYYY-MM-DDTHH:MM:SS.mmmmmm'или'YYYY-MM-DDTHH:MM:SS', например,'2015-10-16T17:49:04.594177'.Параметр
sepразделяет дату и время в выходной строке.
-
__str__()¶ Аналогично
datetime.isocalendar(' ').
-
ctime()¶ Возвращает строковое представление даты, например:
'Wed Dec 4 20:30:40 2002'.
-
strftime(format)¶ -
__format__(format)¶ Возвращает строковое представление времени в заданном формате
format(см. Функции strftime() и strptime()).
-
11.1.2.1.6. Класс tzinfo¶
tzinfo - абстрактный класс, предназначенный для хранения информации временной зоне и летнем/зимнем времени в пределах одного класса.
В модуле datetime уже существует класс timezone, который можно использовать для представления временных зон с фиксированным отклонением, например:
UTC;
MSK (англ. Moscow Time, Московское время);
EST (англ. Eastern Standard Time, Североамериканское восточное время);
и др.
Экземпляр класса-потомка tzinfo может быть передан в конструктор объектов типа datetime и time; при этом атрибуты объектов находятся в местном времени, а tzinfo позволяет найти отклонение от заданного часового пояса.
Методы
-
class
datetime.tzinfo¶ -
utcoffset(dt)¶ Возвращает отклонение местного времени от UTC (в минутах), с учетом как часового пояса, так и летнего/зимнего времени. Если отклонение не известно, должен возвращать
None.Большинство реализаций содержит два варианта:
return CONSTANT # фиксированное отклонение # или return CONSTANT + self.dst(dt) # фиксированное отклонение + летнее/зимнее время.
-
dst(dt)¶ Возвращает отклонение для летнего/зимнего времени (англ. Daylight Saving Time) от UTC (в минутах); если отклонение не известно, должен возвращать
None.
-
tzname(dt)¶ Возвращает наименование (сроку) временной зоны для
datetime-объектаdt(например,'GMT','UTC','EDT','MSK'); если наименование не известно, должен возвращатьNone.
-
fromutc(dt)¶ Возвращает дату/время
dtотносительно UTC.
-
11.1.2.1.7. Класс timezone¶
timezone - класс-потомок tzinfo, реализующий фиксированное отклонение времени от UTC (не учитывает летнее/зимнее время).
Конструкторы
-
class
datetime.timezone(offset[, name])¶ Инициализирует класс-временную зону.
Поля
-
class
datetime.timezone¶ -
utc¶ Возвращает отклонение местного времени от UTC (в минутах), с учетом как часового пояса, так и летнего/зимнего времени. Если отклонение не известно, должен возвращать
None.
-
Методы
-
class
datetime.timezone¶ -
utcoffset(dt)¶ Возвращает фиксированное значение отклонения от UTC (тип
timedelta). Аргументdtигнорируется.
-
dst(dt)¶ Возвращает
None.
-
tzname(dt)¶ Возвращает наименование временной зоны или строку
‘UTCsHH:MM’, если наименование не было задано.
-
fromutc(dt)¶ Возвращает дату/время со сдвигом
offset; аргументdtдолжен быть «осведомленным»datetime-объектом.
-
11.1.2.1.8. Функции strftime() и strptime()¶
Классы date, datetime и time поддерживают гибкое преобразование в строку с помощью функции strftime().
-
class
datetime.datetime¶ -
strftime(format)¶ Возвращает строку по формату
formatдля заданного объекта.
-
Создать экземпляр класса datetime можно используя «обратную» функцию strptime():
-
class
datetime.datetime¶ -
classmethod
strptime(date_string, format)¶ Возвращает
datetime-объект, составленный из строкиdate_stringпо форматуformat.
-
classmethod
Функция strftime() в Python базируется на аналогичной функции языка Си strftime() и поддерживает соответствующие спецификаторы (коды) формата.
В Таблице 11.1.6 приведены некоторые значения кодов формата.
Код |
Описание |
Пример |
|---|---|---|
|
Сокращенное название дня недели * |
|
|
Полное название дня недели * |
|
|
Сокращенное название месяца * |
|
|
Полное название месяца * |
|
|
Представление даты и времени * |
|
|
День месяца (1—31) |
|
|
Представление часов в 24-х часовом формате |
|
|
Представление часов в 12-ти часовом формате |
|
|
День в году (001-365) |
|
|
Номер месяца (01-12) |
|
|
Минуты (00-59) |
|
|
Обозначение AM или PM * |
|
|
Секунды (00-61) |
|
|
Номер недели, первый день недели — воскресенье (0—53) |
|
|
Номер дня недели, начиная с воскресенья (0—6) |
|
|
Номер недели, первый день недели — понедельник (0—53) |
|
|
Представление даты * |
|
|
Представление времени * |
|
|
Год, последние две цифры |
|
|
Год, полная запись |
|
|
Название или аббревиатура временной зоны |
|
|
Символ процента |
|
* используется текущая локаль. Для того, чтобы отобразить наименования на русском, необходимо предварительно переключиться на русскую локаль (см. модуль locale).
Подробнее формат и поведение функций strftime() и strptime() описаны в справке.
Общий пример использования классов модуля datetime приведен в Листинге 11.1.4.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | import datetime
# Приветствие в зависимости от времени суток
t1 = datetime.datetime.now().time()
hours = t1.hour + 1
if 6 <= hours <= 10:
print("Доброе утро!")
elif 10 < hours <= 18:
print("Добрый день!")
else:
print("Доброй ночи!")
print()
# Местное и UTC-время
print("Местное и UTC-время")
d1 = datetime.datetime.utcnow()
d2 = datetime.datetime.now()
td = d1 - d2
print(d1.strftime("%d/%m/%Y %H:%M"), "|", d1) # 23/12/2015 00:14 | 2015-12-23 00:14:07.286454
print(d2.strftime("%d/%m/%Y %H:%M"), "|", d2) # 23/12/2015 03:14 | 2015-12-23 03:14:07.286458
print("Разница = {}\n".format(abs(td))) # Разница = 3:00:00.000004
# Время до события: datetime, timedelta
d1 = datetime.datetime.strptime("14/06/2018 18:00", "%d/%m/%Y %H:%M")
d2 = datetime.datetime.now()
td = d1 - d2
print("До 1 матча ЧМ 2018 по футболу осталось")
print(" 1-й матч: {}".format(d1.ctime())) # Thu Jun 14 18:00:00 2018
print(" Сейчас: {}".format(d2.strftime("%a %b %d %H:%M:%S %Y")))
print(" Осталось: {} дн. {} ч. {} мин.".
format(td.days, td.seconds//3600, td.seconds//60 % 60))
# -------------
# Пример вывода:
# Доброй ночи!
#
# Местное и UTC-время
# 23/12/2015 00:14 | 2015-12-23 00:14:07.286454
# 23/12/2015 03:14 | 2015-12-23 03:14:07.286458
# Разница = 3:00:00.000004
#
# До 1 матча ЧМ 2018 по футболу осталось
# 1-й матч: Thu Jun 14 18:00:00 2018
# Сейчас: Wed Dec 23 03:14:07 2015
# Осталось: 904 дн. 14 ч. 45 мин.
|
11.1.2.2. Модуль time¶
Модуль time содержит функции для работы с временем. Большинство функций является аналогом соответствующих функция языка Си (синтаксис и возможности могут различаться в зависимости от используемой платформы).
Основные термины и особенности:
эра (англ. Unix Epoch): количество секунд, прошедших с полуночи (00:00:00 UTC) 1 января 1970 года (четверг) (Рисунок 11.1.1);
функции могут не работать с датами вне промежутка от начала эпохи до 2038 г. (проблема 2038 года, Рисунок 11.1.2);
отсутствует проблема 2000 года (Рисунок 11.1.3).



Некоторые функции:
-
time.ctime([seconds])¶ Возвращает строку, содержащую время по истечении
secondsсекунд с момента начала эпохи.
-
time.perf_counter()¶ Возвращает доли секунды с момента начала работы ОС. Может использоваться для измерения достаточно малого промежутка времени.
-
time.sleep(seconds)¶ Приостанавливает поток выполнения программы на
secondsсекунд (аргумент может быть вещественным - долей секунды).
Пример использования модуля приведен в Листинге 11.1.5.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | import time
# Приложение имитирует индикатор прогресса во время установки приложения
print("Добро пожаловать в инсталлятор! Нажмите <ENTER> для продолжения...")
input()
print(time.ctime(60*60*24*365*45)) # Sun Dec 21 03:00:00 2014
sec_start = time.perf_counter()
for i in range(100):
print("#", end="", flush=True)
# "Засыпаем" на 50 мс.
time.sleep(0.05)
if (i + 1) % 10 == 0:
print(" {:3}%".format(i + 1))
sec_end = time.perf_counter()
print("Программа успешно установлена за {:.2f} с.".format(sec_end - sec_start))
# -------------
# Пример вывода:
# Добро пожаловать в инсталлятор! Нажмите <ENTER> для продолжения...
#
# Sun Dec 21 03:00:00 2014
# ########## 10%
# ########## 20%
# ########## 30%
# ########## 40%
# ########## 50%
# ########## 60%
# ########## 70%
# ########## 80%
# ########## 90%
# ########## 100%
# Программа успешно установлена за 5.01 с.
|
11.1.2.3. Модуль calendar¶
Модуль calendar содержит классы для работы с календарем (Таблица 11.1.7).
Класс |
Описание |
|---|---|
|
Базовый класс для создания календарей |
|
Класс для создания календарей в текстовом виде |
|
Класс для создания календарей в текстовом виде с учетом локали |
|
Класс для создания календарей в HTML-формате |
|
Класс для создания календарей в HTML-формате с учетом локали |
Пример использования модуля приведен в Листинге 11.1.6.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | import calendar
import datetime
# Текстовый календарь на текущий месяц
c = calendar.TextCalendar()
d = datetime.date.today()
s = c.formatmonth(d.year, d.month)
print("Сегодня: {}\n\n{}".format(d, s))
# -------------
# Пример вывода:
# Сегодня: 2015-12-23
#
# December 2015
# Mo Tu We Th Fr Sa Su
# 1 2 3 4 5 6
# 7 8 9 10 11 12 13
# 14 15 16 17 18 19 20
# 21 22 23 24 25 26 27
# 28 29 30 31
|
11.1.2.4. Пакет pytz¶
Сторонний пакет pytz содержит данные о всех временных зонах согласно базе данных часовых поясов (или «базе данных Олсона»).
Пример использования пакета приведен в Листинге 11.1.7.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | import pytz
import datetime
ALIGN_FIX = 20
# Список идентификаторов находится в pytz.all_timezones или common_timezones
# for tz in pytz.all_timezones:
# print(tz)
# print(pytz.common_timezones)
# Временная зона MSK
tz_msk = pytz.timezone("Europe/Moscow")
dt1 = datetime.datetime.now(tz_msk)
print("{:>{}}: {}".format("Московское время", ALIGN_FIX, dt1))
print("{:>{}}: {}".format("UTC-время", ALIGN_FIX, dt1.astimezone(pytz.utc)))
print("{:>{}}: {}".format("Отклонение от UTC", ALIGN_FIX, dt1.utcoffset()))
print("{:>{}}: {}".format("Сдвиг лето/зима", ALIGN_FIX, dt1.dst()))
# Временные зоны можно использовать из модуля pytz или
# создать собственные, используя datetime.timezone
tz_bj = datetime.timezone(datetime.timedelta(hours=8), "China/Beijing")
tz_pa = pytz.timezone("Europe/Paris")
tz_wa = pytz.timezone("US/Pacific")
print("{:>{}}: {}".format("Пекин", ALIGN_FIX, dt1.astimezone(tz_bj)))
print("{:>{}}: {}".format("Париж", ALIGN_FIX, dt1.astimezone(tz_pa)))
print("{:>{}}: {}".format("Нью-Йорк", ALIGN_FIX, dt1.astimezone(tz_wa)))
# -------------
# Пример вывода:
# Московское время: 2015-12-25 15:05:18.225371+03:00
# UTC-время: 2015-12-25 13:27:57.220009+00:00
# Отклонение от UTC: 3:00:00
# Сдвиг лето/зима: 0:00:00
# Пекин: 2015-12-25 21:27:57.220009+08:00
# Париж: 2015-12-25 14:27:57.220009+01:00
# Нью-Йорк: 2015-12-25 05:27:57.220009-08:00
|
11.1.2.5. Модуль locale¶
Модуль locale предоставляет доступ к набору локалей и реализован на базе соответствующего модуля языка Си. Механизм локалей позволяет взаимодействовать с национальными особенностями системы (языковыми, культурными и т.д.).
Некоторые функции:
-
locale.setlocale(category, locale=None)¶ Устанавливает локаль для категории
categoryв значениеlocale, если оно не равноNone. В качестве категории может использоваться любое предопределенное значение, напримерlocale.LC_ALL(все настройки),locale.LC_TIME(настройки отображения времени) и т.д.
-
locale.getlocale(category=LC_CTYPE)¶ Возвращает текущую локаль для заданной категории.
Пример использования модуля приведен в Листинге 11.1.8.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 | import calendar
import datetime
import locale
# Доступные локали:
# - Windows: https://msdn.microsoft.com/en-us/goglobal/bb895996.aspx
# - Unix: команда $locale -a
# 1) Разница в выводе даты/времени в разной локали
d = datetime.datetime.now()
fmt = "%d/%B/%Y %A %H:%M:%S"
print(d.strftime(fmt)) # 25/December/2015 Friday 15:20:14
locale.setlocale(locale.LC_ALL, "Russian") # ru_RU.utf8 для Unix
print(d.strftime(fmt)) # 25/Декабрь/2015 пятница 15:20:14
locale.setlocale(locale.LC_ALL, "English") # C.UTF-8 для Unix
print(d.strftime(fmt)) # 25/December/2015 Friday 15:20:14
# 2) Текстовый календарь на текущий месяц
locale.setlocale(locale.LC_ALL, "Russian")
c = calendar.LocaleTextCalendar(0, "Russian")
# Текущая локаль
print("\n{}".format(locale.getlocale(locale.LC_ALL))) # ("Russian_Russia", "1251")
s = c.formatmonth(d.year, d.month)
print("\n{}".format(s))
# -------------
# Пример вывода:
# 25/December/2015 Friday 15:20:14
# 25/Декабрь/2015 пятница 15:20:14
# 25/December/2015 Friday 15:20:14
#
# ("Russian_Russia", "1251")
#
# Декабрь 2015
# Пн Вт Ср Чт Пт Сб Вс
# 1 2 3 4 5 6
# 7 8 9 10 11 12 13
# 14 15 16 17 18 19 20
# 21 22 23 24 25 26 27
# 28 29 30 31
|
11.1.3. Платформа и операционная система¶
Python предоставляет множество модулей для работы с платформой и операционной системой (ОС), которые поддерживают как зависимые, так и независимые от конкретной платформы функции.
К наиболее часто используемым модулям/пакетам относятся:
Модуль / Пакет |
Описание |
|---|---|
Переменные и функции, которые используются/взаимодействуют с интерпретатором |
|
Низкоуровневая информация о платформе |
|
Унифицированный способ доступа к системным функциям для разных платформ |
|
Функции для работы с именами путей в ОС |
|
Высокоуровневые операции с файлами (копирование, удаление и др.) |
|
Запуск процессов, присоединение к потокам их ввода/вывода и получение кодов возврата |
|
Поиск путей по заданной маске |
11.1.3.1. Системные операции¶
Платформа
-
platform.machine()¶ Возвращает тип машины, например,
'i386'.Если определить не возможно, возвращается пустая строка.
-
platform.node()¶ Возвращает сетевое имя машины.
Если определить не возможно, возвращается пустая строка.
-
platform.platform(aliased=0, terse=0)¶ Возвращает имя платформы в «человекочитаемом» виде, например:
'Windows-10-10.0.14393-SP0'.
-
platform.processor()¶ Возвращает наименование процессора, например:
'Intel64 Family 6 Model 58 Stepping 9, GenuineIntel'.
-
platform.system()¶ Возвращает название операционной системы, например:
'Windows'.
-
platform.version()¶ Возвращает версию операционной системы, например:
'10.0.14393'.
-
platform.uname()¶ Возвращает именованный кортеж из результатов вызова функций:
(system(), node(), release(), version(), machine(), processor()).
Операционная система
-
sys.byteorder¶ Порядок байтов в ОС:
'big'(от старшего к младшему) или'little'(от младшего к старшему).
-
sys.float_info¶ Возвращает информацию о типе
float(например, максимально и минимально доступное значение) на текущей платформе.
-
sys.getfilesystemencoding()¶ Возвращает наименование кодировки по умолчанию для ОС (используется для преобразования из/в Юникод); например,
'utf-8'для Mac OS X или'mbcs'для Windows.
-
sys.getsizeof(object[, default])¶ Возвращает размер
objectв байтах.
-
sys.maxsize¶ Наибольшее целое число, поддерживаемое ОС.
-
sys.platform¶ Строка, содержащая идентификатор платформы.
Пример:
'win32'для Windows,'linux'для Linux,'darwin'для Mac OS X.
-
shutil.disk_usage(path)¶ Возвращает именованный кортеж, содержащий значения общего, используемого и свободного пространства в директории
path(в байтах).
Интерпретатор
-
sys.copyright¶ Строка-copyright интерпретатора Python.
-
sys.exc_info()¶ Возвращает кортеж из трех значений, содержащий информацию об текущем исключении
(type, value, traceback):type- класс ошибки;value- экземпляр класса;traceback- объект, включающий стек вызовов.
Если исключение не обрабатывается в текущий момент, элементы кортежа равны
None.
-
sys.getrefcount(object)¶ Возвращает количество ссылок на объект.
Как правило, возвращаемое число на единицу больше, т.к. сам аргумент
objectидет в счет.
-
sys.path¶ Список строк, определяющих пути поиска модулей.
Инициализируется на основании переменной окружения PYTHONPATH, а также прочих установок.
-
sys.version_info()¶ Кортеж из 5-ти чисел, обозначающих версию Python
(major, minor, micro, releaselevel, serial).
Процессы, пользователи, командная строка
-
os.environ¶ Объект (словарь), содержащий значения переменных среды (окружения).
Если значение не найдено, возбуждается исключение
KeyError. Также существует альтернативная функцияos.getenv(name), возвращающаяNoneв случае отсутствия значения.Пример:
os.environ['HOME']илиos.getenv('HOME')вернет домашний каталог пользователя, а при параметреLOGNAME- имя текущего пользователя.
-
os.startfile(path[, operation])¶ Запускает файл в приложении по умолчанию.
Только для Windows.
-
subprocess.run(args, *, stdin=None, input=None, stdout=None, stderr=None, shell=False, timeout=None, check=False, encoding=None, errors=None)¶ Запускает команду из
args, ожидая завершения процесса и возвращая результат выполнения.
-
sys.argv¶ Список аргументов командной строки.
Как правило,
argv[0]- имя скрипта (абсолютный/относительный путь - зависит от ОС). Далее идут другие аргументы (при наличии).
-
sys.exit([arg])¶ Выход из Python.
Реализовано как возбуждение исключения SystemExit.
Аргумент
arg- код возврата командной строки (по умолчанию 0, т.е. «успешное завершение»), большинство ОС поддерживает числа 0-127, где отличное от 0 значение свидетельствует об ошибке.
Пример использования ряда указанных функций приведен в Листинге 11.1.9.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | import sys
import os
import platform
import subprocess
# Создадим файл с информацией о платформе/ОС и откроем его
# в редакторе по умолчанию
if __name__ == "__main__":
# Путь (относительный) к файлу с данными
# Создание файла будет происходить в рабочей директории
data_filename = "data.txt"
# Создаем файл
with open(data_filename, "w", encoding="utf-8") as fh:
fh.write("Файл с данными: {}\n\n".format(data_filename))
fh.write("os.environ")
for name in sorted(os.environ):
fh.write(" {} = {}\n".format(name, os.environ[name]))
fh.write("\nsys.copyright = {}\n\n".format(sys.copyright))
fh.write("sys.version_info = {}\n\n".format(sys.version_info))
fh.write("sys.path = {}\n\n".format(sys.path))
fh.write("sys.argv = {}\n\n".format(sys.argv))
fh.write("sys.byteorder = {}\n\n".format(sys.byteorder))
fh.write("sys.getfilesystemencoding() = {}\n\n".
format(sys.getfilesystemencoding()))
fh.write("sys.maxsize = {}\n\n".format(sys.maxsize))
fh.write("platform.uname() = {}".format(platform.uname()))
# Открываем получившийся файл в приложении по умолчанию
if platform.system() == "Windows":
os.startfile(data_filename)
else:
subprocess.run(["xdg-open", data_filename])
|
11.1.3.2. Операции над путями файловой системы¶
Константы
-
os.curdir¶ Константа, обозначающая текущую директорию.
'.'для Windows и POSIX (стандарт обеспечения совместимости различных UNIX-подобных операционных систем).
-
os.pardir¶ Константа, обозначающая родительскую директорию.
'..'для Windows и POSIX.
-
os.sep¶ Символ, ипользуемый для разделения компонентов пути в файловой системе.
'/'для POSIX и'\'для Windows.Примечание
Для соединения и разбиения путей лучше использовать функции
os.path.join()иos.path.split()соответственно.
-
os.linesep()¶ Символ-завершение строки на текущей платформе.
Пример
'\n'для POSIX и'\r\n'для Windows.Примечание
Не следует использовать данную константу при записи файлов - для переноса всегда лучше использовать
'\n', Python сам выполнит нужное преобразование.
Абсолютные и относительные пути
-
os.getcwd()¶ Возвращает строку, содержащую путь к рабочему каталогу (каталогу файловой системы, который используется для нахождения файлов, указанных только по имени либо по относительному пути).
-
os.path.isabs(path)¶ Возвращает
True, если путь является абсолютным.
-
os.path.normpath(path)¶ Возвращает нормализованный путь, убирая лишние разделители и специальные символы (например, родительской директории).
-
os.path.realpath(path)¶ Возвращает канонический путь, убирая символические ссылки из пути.
-
os.path.relpath(path, start=os.curdir)¶ Возвращает путь для
pathотносительно путиstart.
Склейка и разбиение путей
-
os.path.dirname(path)¶ Возвращает имя директории для пути
path.
-
os.path.join(path, *paths)¶ Возвращает строку, соединив параметры в путь, используя нужный разделитель.
-
os.path.split(path)¶ Разбивает строку
pathна пару(head, tail):tail- последний компонент пути;head- все остальное.
-
os.path.splitdrive(path)¶ Разбивает строку
pathна пару(drive, tail),drive- точка подключения или диск.
-
os.path.splitext(path)¶ Разбивает строку
pathна пару(root, ext), так чтоroot + ext == path.
11.1.3.3. Операции с файлами и директориями¶
Создание файлов и директорий
-
os.mkdir(path, mode=0o777, *, dir_fd=None)¶ Создает директорию
pathс заданными правами доступа.
-
os.makedirs(name, mode=0o777, exist_ok=False)¶ Рекурсивно создает директории в пути
path.Если
exist_ok == Falseи папка уже существует, возбуждается исключениеOSError.
Удаление файлов и директорий
-
os.remove(path, *, dir_fd=None)¶ Удаляет файл
path.Если
path- директория, возбуждается исключениеOSError.
-
os.rmdir(path, *, dir_fd=None)¶ Удаляет директорию
path.Если удаление не удается или папка не пуста, возбуждается исключение
OSError.
-
os.removedirs(name)¶ Рекурсивно удаляет директории в пути
path.Если удаление не удается, возбуждается исключение
OSError.
-
shutil.rmtree(path, ignore_errors=False, onerror=None)¶ Выполняет рекурсивное удаление директории
path.Если
ignore_errors == True, при ошибке удаление возбуждается исключение или вызывается обработчикonerror.
Переименование файлов и директорий
-
os.rename(src, dst, *, src_dir_fd=None, dst_dir_fd=None)¶ -
os.replace(src, dst, *, src_dir_fd=None, dst_dir_fd=None)¶ Переименовывает файл
srcвdst.Если файл существует,
os.replaceперезаписывает его,os.renameкак правило, возбуждает исключениеOSError.Если удаление не удается или
dst- папка, возбуждается исключениеOSError.
-
os.renames(old, new)¶ Рекурсивно переименовывает файл или директорию.
Копирование, перемещение файлов и директорий
-
shutil.copyfile(src, dst, *, follow_symlinks=True)¶ Копирует содержимое файла
src(без метаданных) в файлdst, возвращаяdst:src- имя исходного файла;dst- имя конечного файла;follow_symlinks- если равенFalse, копируется ярлык, еслиTrue- сам файл, на который он указывает.
-
shutil.copymode(src, dst, *, follow_symlinks=True)¶ Копирует права доступа от
srcвdst.
-
shutil.copystat(src, dst, *, follow_symlinks=True)¶ Копирует права доступа, время последнего доступа, модификации и флаги от
srcвdst.
-
shutil.copy(src, dst, *, follow_symlinks=True)¶ Копирует файл
srcв файлdst, возвращая путь к новому файлу.Если
dst- папка, берется исходное имя файла.Данная функция копирует только содержимое и права доступа.
-
shutil.copy2(src, dst, *, follow_symlinks=True)¶ Аналог
shutil.copy(), но по возможности копирует все метаданные.
-
shutil.copytree(src, dst, symlinks=False, ignore=None, copy_function=copy2, ignore_dangling_symlinks=False)¶ Выполняет рекурсивное копирование директории
srcвdstвозвращая имя конечной директории.dstне должна существовать перед выполнением операции.Для директорий права доступа и время модификации копируется функцией
copystat(), файлы копируются с использованиемshutil.copy2().
-
shutil.move(src, dst, copy_function=copy2)¶ Выполняет рекурсивное перемещение файла или директории
srcвdst.
Поиск файлов и директорий
-
os.scandir(path='.')¶ Возвращает итератор файловых объектов в директории
path, который не содержит специальные имена'.'and'..'.
-
glob.glob(pathname, *, recursive=False)¶ Возвращает список путей, отвечающих заданной маске в пути
pathname.Если
recursive == True, поиск выполняется рекурсивно (во вложенных папках).
Проверка типа файловых объектов
-
os.path.exists(path)¶ Возвращает:
True: еслиpathсуществует или является дескриптором открытого файла;False: для ссылок (ярлыков), а также при отсутствии доступа к пути.
-
os.path.getsize(path)¶ Возвращает размер в байтах
path.Если файл не доступен или не существует, возбуждается исключение
OSError.
-
os.path.isfile(path)¶ Возвращает
True, если файлpathсуществует.Это справедливо и для ссылок, поэтому
islink()также может возвращатьTrue.
-
os.path.isdir(path)¶ Возвращает
True, если директорияpathсуществует.Это справедливо и для ссылок, поэтому
islink()также может возвращатьTrue.
-
os.path.islink(path)¶ Возвращает
True, еслиpath- символическая ссылка (ярлык).
Пример использования ряда указанных функций приведен в Листинге 11.1.10.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 | import sys
import os
import os.path
import glob
import shutil
# Скопируем все *.py файлы из директории скрипта
# в дочернюю папку Scripts
if __name__ == "__main__":
# 1) Определяем пути
# Абсолютный путь к скрипту
app_path = os.path.dirname(os.path.realpath(sys.argv[0]))
# 2) Создаем папку Scripts
scripts_path = os.path.join(app_path, "Scripts")
# Если папка уже есть - удаляем по запросу и выходим
if os.path.exists(scripts_path):
answer = input("Уже копировали ранее! Удалить папку? (y/n) ").upper()
if answer == "Y":
shutil.rmtree(scripts_path)
print("Папка удалена.")
sys.exit("Программа будет завершена.") # Выход из скрипта
os.makedirs(scripts_path, exist_ok=True)
# 3) Находим и копируем файлы
filenames = glob.glob(os.path.join(app_path, "*.py"))
for filename in filenames:
if os.path.isfile(filename):
shutil.copy2(filename, scripts_path)
# 4) Отображаем файлы из новой директории
filenames_new = os.listdir(scripts_path)
print("Найдено скопированных файлов: {}".format(len(filenames_new)))
for filename in sorted(filenames_new):
print(" - {} | {:.2f} Кб".
format(filename, os.path.getsize(filename) / 1024))
# -------------
# Пример вывода:
#
# Найдено скопированных файлов: 9
# - 01_01_19.py | 0.52 Кб
# - 02_01_01.py | 0.21 Кб
# - 02_01_02.py | 0.19 Кб
# - 02_01_03.py | 0.81 Кб
# - 02_01_04.py | 0.32 Кб
# - 02_01_05.py | 0.55 Кб
# - 02_01_06.py | 0.26 Кб
# - 02_01_07.py | 0.59 Кб
# - 02_02_01.py | 0.82 Кб
|
11.1.4. Регулярные выражения¶
Регулярные выражения (англ. Regular Expressions) - это компактная форма записи (шаблон, маска или паттерн) представления о коллекции строк. Гибкость и мощь регулярных выражений обусловлена тем, что единственное регулярное выражение может представлять неограниченное число строк, подходящий под заданный шаблон.
Регулярные выражения используются для достижения четырех основных целей:
Проверка
Проверка соответствия фрагментов текста некоторым критериям. Например, наличие символа обозначения валюты и последующих за ним цифр, проверка адреса электронной почты и т.д.
Поиск
Поиск подстрок, которые в том числе могут иметь несколько форм. Например, поиск
'pet.png','pet.jpg','pet.jpeg'или'pet.svg', чтобы при этом не обнаруживались подстроки'carpet, png'и подобные ей.Замена
Замена всего, что совпадает с шаблоном, на указанную строку. Например, поиск подстроки
'устройство передвижения, движимое мускульной силой'и замена подстрокой'велосипед'.Разбиение строк
Разбиение строки по точкам совпадения с шаблоном. Например, разбиение строки по
':'или'='.
Примечание
Для написания и отладки регулярных выражений удобно использовать онлайн-сервисы, например https://regex101.com, которые в том числе содержат библиотеку готовых выражений и могут генерировать код для различных языков программирования.
11.1.4.1. Язык регулярных выражений¶
Регулярные выражения являются строкой-шаблоном для поиска, определяются с помощью мини-языка и могут содержать:
Флаги.
Символы и классы символов.
Квантификаторы.
Группировка и выбор.
Проверка границ (привязки).
11.1.4.1.1. Флаги¶
Флаги не входят непосредственно в регулярное выражение, однако расширяют его функции. Типичные флаги (указываются после выражения):
'g'- глобальный поиск (обрабатываются все совпадения с шаблоном поиска);'i'- регистр букв не имеет значения (по умолчанию любой поиск регистрозависим);'m'- многострочный поиск;и др.
Флаг указывается после паттерна, например: '/[0-9]/m'.
11.1.4.1.2. Символы и классы символов¶
Поиск символов и строк
Одним из наиболее простых случаев является поиск отдельных символов и строк (Рисунок 11.1.4).
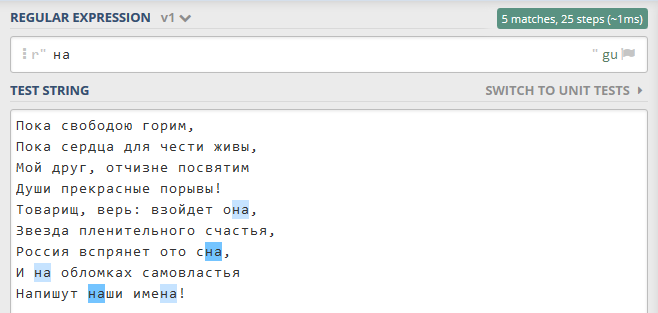
Рисунок 11.1.4 - Поиск в тексте подстроки 'на': https://regex101.com/r/QcIOZI/1¶
Большинство символов могут использоваться как литералы, однако некоторые имеют «специальное назначение» в языке регулярных выражений и потому должны экранироваться символом обратного слеша '\', когда они используются как литералы.
К специальным символам (также символам-джокерам или символам подстановки) относятся:
\ . ~ $ ? + * { } [ ] ( ) |
В пределах регулярных выражений можно также использовать большинство стандартных экранированных последовательностей языка Python, например, '\n', '\t' и др.
Поиск множества символов
Для поиска не конкретной последовательности символов, а некоторого их множества предназначены классы символов.
- „[группа_символов]“
Соответствует любому одиночному символу, входящему в
группа_символов. По умолчанию при сопоставлении учитывается регистр.Пример:
выражение
'[аеёиоуэюя]'позволяет найти все гласные буквы в строке;выражение
'п[ое]л'даст совпадение для слов'пел'и'пол', но не найдет слова'поел'или'пил'.
- „[^группа_символов]“
Соответствует любому одиночному символу, НЕ входящему в
группа_символов. По умолчанию при сопоставлении учитывается регистр.Пример:
выражение
'[^аеёиоуэюя]'обнаружит все символы в тексте, кроме гласных букв.
- „[первый-последний]“
Диапазон символов: соответствует одному символу в диапазоне от
первыйдопоследний.Пример:
выражение
'[0-9]'найдет все цифры тексте.
- „.“ (точка)
Специальный знак
'.'соответствует какому-либо одному знаку, кроме'\n'. Для поиска точки необходимо использовать экранирование:'\.'.Пример:
выражение
'м.л'найдет в тексте'мел','мул'и т.д.
- „\w“
Соответствует любому алфавитно-цифровому знаку.
Пример:
выражение
'\w1'найдет в тексте'11'или'я1'.
- „\W“
Соответствует любому символу, НЕ являющимся алфавитно-цифровым знаком.
- „\s“
Соответствует любому пробельному символу (пробел, табуляция и др.).
- „\S“
Соответствует любому знаку, НЕ являющемуся пробельным.
- „\d“
Соответствует любой десятичной цифре.
Пример:
выражение
'\d-й'найдет в тексте'1-й'или'2-й'.
- „\D“
Соответствует любому символу, НЕ являющемуся десятичной цифрой.
Предупреждение
При использовании онлайн-сервисов будьте внимательны - некоторые не поддерживает Юникод в полном объеме, поэтому, например, выражение '\w' может не находить кириллицу в тексте. В Python данной проблемы нет.
11.1.4.1.3. Квантификаторы¶
Зачастую требуется не только найти слово по символам или группе символов, но и указать количество возможных повторений, для чего в регулярных выражениях используются квантификаторы.
Квантификаторы записываются после символа/строки/множества (Таблица 11.1.8).
Квантификатор |
Описание |
|---|---|
|
Ноль или более совпадений |
|
Одно или больше совпадений |
|
Ноль или одно совпадение |
|
Совпадение ровно |
|
Совпадение |
|
Совпадение от |
Каждый квантификатор может быть:
жадный (англ. greedy): находит как можно больше подходящих символов;
ленивый (англ. lazy): находит как можно меньше подходящих символов.
По умолчанию, все квантификаторы являются жадными; для включения «ленивого» режима необходимо поставить знак '?' после квантификатора.
На Рисунках 11.1.5 (а-б) приведен пример использования квантификаторов.

Рисунок 11.1.5 (а) - Поиск нескольких единиц в телефонных номерах с использованием квантификатора: https://regex101.com/r/Hhcs5Q/1¶
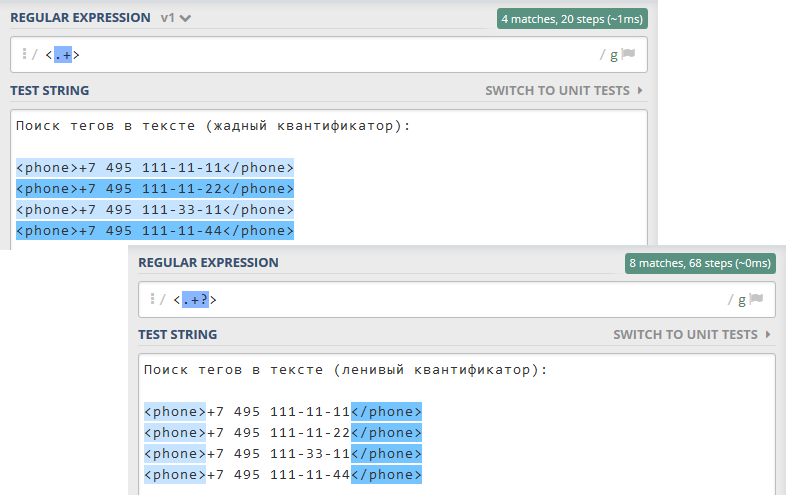
Рисунок 11.1.5 (б) - Разница между жадным и ленивым режимом: https://regex101.com/r/T5IJ4b/1¶
11.1.4.1.4. Группировка и выбор¶
В случае, когда необходим поиск подстроки с сохранением для дальнейшей обработки или выбор варианта поиска, регулярные выражения предлагают операции группировки '( )' и выбора '|' соответственно.
Группировка
Группировка '( )' преследует 2 цели: сгруппировать шаблон поиска (группировка) и использовать его в дальнейшем (группировка с сохранением или захватом).
Обращение к захваченной группе возможно:
по индексу:
'\i', гдеi- это порядковый номер группы;по имени:
'\k<Название>', если группа была именованой.
- „(часть_выражения)“
Захватывает, соответствующие выражения и присваиваем им нумерацию, начиная с 1.
Пример:
выражение
'(\w+)\s+\1'выполнит в тексте поиск повторяющихся слов, разделенных пробельным символом (пример упрощен); при этом первое слово будет захвачено в отдельную группу под номером1(Рисунок 11.1.6 (а)).

Рисунок 11.1.6 (а) - Нумерованная группа в регулярном выражении: https://regex101.com/r/KmlDRh/1¶
- „(?<имя>часть_выражения)“
Выделяет соответствующую часть выражения в именованную группу. Именованные группы удобно использовать в длинных или сложных регулярных выражениях.
Пример:
выражение
'(?<word>\w+)\s+\k<word>'выполнит в тексте поиск повторяющихся слов, разделенных пробельным символом (паттерн очень упрощен); при этом первое слово будет захвачего в отдельную группу под именемword(Рисунок 11.1.6 (б)).
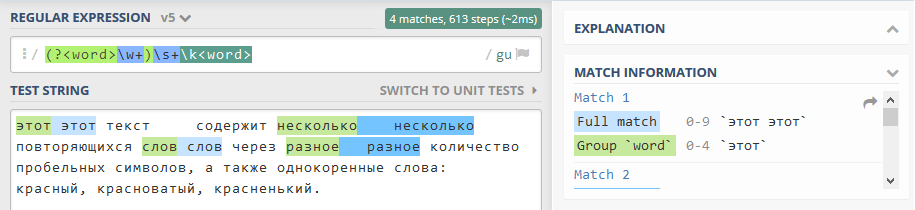
Рисунок 11.1.6 (б) - Именованная группа в регулярном выражении: https://regex101.com/r/KmlDRh/5¶
- „(?:часть_выражения)“
Определяет невыделяемую группу (без захвата).
Пример:
выражение
'(?:\w+)\s'выполнит в тексте поиск слов, отделенных пробельным символом; при этом слово НЕ будет захвачено в отдельную группу (Рисунок 11.1.6 (в)).
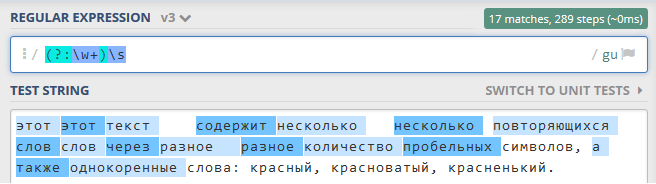
Рисунок 11.1.6 (в) - Невыделяемая группа в регулярном выражении: https://regex101.com/r/KmlDRh/3¶
Выбор
Операция выбора позволяет захватить одно из нескольких выражений в качестве результата поиска.
- „выражение1|выражение2|выражение3“
Соответствует любому элементу, разделенному вертикальной чертой
'|'.Пример:
выражение
'красн(?:ый|оватый|енький)'найдет в тексте слова'красный','красноватый','красненький'; при этом окончание не будет захвачено в группу (Рисунок 11.1.6 (г)).
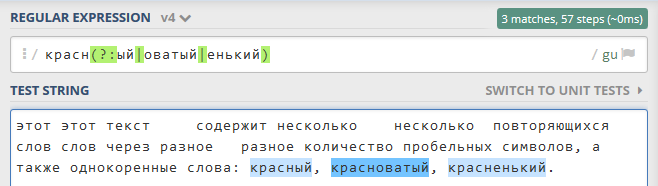
Рисунок 11.1.6 (г) - Выбор в регулярном выражении: https://regex101.com/r/KmlDRh/4¶
11.1.4.1.5. Проверка границ (привязки)¶
Регулярные выражения также позволяют контролировать границы поиска текста (Таблице 11.1.9).
Утверждение |
Описание |
|---|---|
|
Соответствие должно начинаться в начале строки или после знака переноса (для каждой строки в многострочном режиме) |
|
Соответствие должно обнаруживаться в конце строки или до символа |
|
Соответствие должно обнаруживаться в начале строки |
|
Соответствие должно обнаруживаться в конце строки или до символа |
|
Соответствие должно обнаруживаться в конце строки |
|
Соответствие должно обнаруживаться в той точке, где заканчивается предыдущее соответствие |
|
Соответствие должно обнаруживаться на границе между символом |
|
Соответствие не должно обнаруживаться на границе |
На Рисунке 11.1.7 приведен пример поиска всех первых слов в начале новой строки.
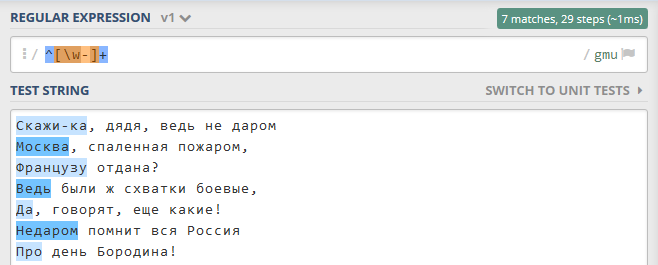
Рисунок 11.1.7 - Поиск всех первых слов в начале новой строки: https://regex101.com/r/ADwhGz/1¶
11.1.4.2. Модуль re¶
Для работы с регулярными выражениями в Python доступен стандартный модуль re.
Предварительно Python выполняет компиляцию регулярного выражения - перевод заданного выражения во внутренний формат. В виду этого существует 2 способа работы:
Если предполагается однократная проверка, достаточно использовать функции модуля
re. При этом во время вызова функции, произойдет компиляция регулярного выражения и дальнейший поиск соответствий.Если проверка будет осуществляется не один раз, эффективным будет предварительно один раз скомпилировать выражение (получив специальный объект класса
re.regex), а затем использовать его методы.
В коде регулярные выражения обычно записываются в виде «сырых» строк (с префиксом r, подавляющих экранирование). Так, при поиске переноса строки удобнее указать r"\n" вместо "\\n", избежав необходимости дублировать экранирующий символ.
11.1.4.2.1. Функции, константы и исключения¶
Константы
Механизм регулярных выражений в языке Python предоставляет возможность устанавливать флаги, влияющие на работу регулярных выражений. Обычно флаги устанавливаются при вызове функции re.compile().
-
re.IGNORECASE¶ Флаг проверки регулярного выражения без учета регистра. Не зависит от текущей локали.
-
re.MULTILINE¶ Флаг включения многострочного режима. При этом
'^'определяет начало, а'$'- окончание каждой строки (без этого режима, определяется соответствие до первого символа переноса строки).
-
re.DOTALL¶ Флаг включает соответствие
'.'любому символу, включая перенос строки.
Функции
-
re.compile(pattern, flags=0)¶ Компилирует регулярное выражение
pattern, используя флагиflags(например,re.MULTILINE) и возвращая объект классаre.regex.Пример:
regex = re.compile("^.+?(\d)")
-
re.search(pattern, string, flags=0)¶ Сканирует строку
stringна первое вхождение регулярного выражения. Возвращает:Если результат функции - не
None, возможно два сценария работы:если достаточно было найти первое вхождение, можно использовать имеющийся объект
re.match;если необходимо найти все вхождения, следует воспользоваться функциями
re.finditer()илиre.findall().
-
re.split(pattern, string, maxsplit=0, flags=0)¶ Возвращает список - результат разбиения строки
stringпо совпадениям шаблонаpattern.Последним элементом всегда идет «остаток» строки,
maxsplit- количество разбиений (0 - любое).
-
re.findall(pattern, string, flags=0)¶ Возвращает список строк всех неперекрывающихся совпадений, просматривая текст для поиска слева направо. Если в регулярном выражении используется группировка, она возвращается в списке в виде кортежа.
Пример:
re.findall(r"\d+", "123aaa bb456b ccc789") # ['123', '456', '789']
-
re.finditer(pattern, string, flags=0)¶ Возвращает итератор, возвращающий объект класса
re.matchдля каждого непересекающегося совпадения регулярного выражения в строке.Пример:
for match in re.finditer(r"\d+", "123aaa bb456b ccc789"): print(match)
-
re.sub(pattern, repl, string, count=0, flags=0)¶ Возвращает строку
string, в которой произведена замена всех неперекрывающихся совпадений с шаблономpatternна строкуrepl. Еслиrepl- функция, она вызывается для каждого совпадения.Пример:
re.sub(r"\D+", "_", "123aaa bb456b ccc789") # '123_456_789'
-
re.escape(string)¶ Возвращает строку
string, экранируя все символы кроме ASCII, чисел и'_'. Удобно использовать, если в регулярном выражении необходимо отследить часть, которая может являться специальным символом.Пример:
regex = re.escape('\d+') # '\\d\+'.
Исключения
-
exception
re.error¶ Возбуждается, когда строка, переданная в качестве регулярного выражения, содержит ошибки (например, нет парной скобки) или произошла ошибка во время компиляции или поиска вхождений.
11.1.4.2.2. Класс regex («регулярное выражение»)¶
-
class
re.regex¶
Объект класса regex является скомпилированным регулярным выражением и имеет ряд атрибутов.
Поля
-
class
re.regex¶ -
flags¶ Флаги, переданные в функцию
re.compile()или записанные непосредственно в регулярном выражении.
-
groups¶ Количество захваченных групп в регулярном выражении.
-
pattern¶ Регулярное выражение в виде, переданном в функцию
re.compile().
-
Методы
-
class
re.regex¶ -
search(string[, pos[, endpos]])¶ Аналогично
re.search().Необязательные параметры
posиendposопределяют начальную и конечную позицию поиска в строке.
-
split(string, maxsplit=0)¶ Аналогично
re.split().
-
findall(string[, pos[, endpos]])¶ Аналогично
re.findall().
-
finditer(string[, pos[, endpos]])¶ Аналогично
re.finditer().
-
11.1.4.2.3. Класс match («совпадение»)¶
-
class
re.match¶
Объект класса match содержит соответствия строки регулярному выражению и имеет ряд атрибутов.
Объекты данного типа всегда равны True, поэтому типовая проверка на вхождение может выглядеть следующим образом:
# Если необходимо первое вхождение
...
match = re.search(pattern, string)
if match:
# Делать что-то с 'match'
...
# Если необходимо найти все вхождения
...
match = re.search(pattern, string)
if match:
for each_match in re.finditer(pattern, string):
# Делать что-то с 'each_match'
...
Поля
-
class
re.match¶ -
pos¶ -
endpos¶ Содержат соответствующие значения, переданные через метод
re.regex.search().
-
re¶ Регулярное выражение, с которым был создан объект.
-
string¶ Строка поиска, с которой был создан объект.
-
Методы
-
class
re.match¶ -
group([group1, ...])¶ Возвращает одну или несколько подгрупп совпадений (если аргумент один - строку, если несколько - кортеж).
Параметр может быть числом или строкой (в случае именованной группы).
Пример:
m = re.search(r"^(\w+) (\w+)", "Никлаус Вирт, ученый в области информатики") >>> m.group(0) # Все совпадение 'Никлаус Вирт' >>> m.group(1) # Первая группа 'Никлаус' >>> m.group(2) # Вторая группа 'Вирт' >>> m.group(1, 2) # 2 группы сразу ('Никлаус', 'Вирт')
-
groups(default=None)¶ Возвращает кортеж, содержащий все группы совпадений или
default.
-
groupdict(default=None)¶ Возвращает словарь, содержащий все именованные группы совпадений или
default.Пример:
>>> m = re.search(r"^(?P<имя>\w+) (?P<фамилия>\w+)", "Никлаус Вирт") >>> m.groupdict() {'имя': 'Никлаус', 'фамилия': 'Вирт'}
-
start([group])¶ -
end([group])¶ Возвращают начальную и конечную позиции вхождения группы
groupили-1, если группа существует, но ей не найдено соответствие.
-
span([group])¶ Возвращает кортеж
(start([group]), end([group])).
-
Пример работы с регулярными выражениями, используя функции и классы модуля re, приведены в Листингах 11.1.11 (а) и (б).
re) | скачать¶1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | import re
# Необходимо найти все e-mail в заданном тексте
# Данные шаблон сильно упрощен для понимания!
# см. http://stackoverflow.com/questions/201323/
# using-a-regular-expression-to-validate-an-email-address
EMAIL_REGEX = r"[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+[a-zA-Z]"
text = """Это произвольный текст, в котором будет происходить поиск
адресов электронной почты (e-mail). Скажу сразу, что мой e-mail
ya@gmail.com; папы и мамы: papa@mail.ru и mama@yandex.ru, а также брата
brat@hotmail.com и даже моего любимого кота: pushok@rambler.ru."""
# 1. Используя re.search() + re.finditer()
m = re.search(EMAIL_REGEX, text, re.MULTILINE)
if m:
for item in re.finditer(EMAIL_REGEX, text):
# 'item' - объект класса match
print("Найден e-mail: {}, позиция {}".format(item.group(0),
item.span()))
else:
print("Ни одного e-mail не найдено!")
# 2. Используя re.findall()
res = re.findall(EMAIL_REGEX, text, re.MULTILINE)
if len(res) > 0:
for item in res: # 'item' - строка
print("Найден e-mail: {}".format(item))
else:
print("Ни одного e-mail не найдено!")
# -------------
# Пример вывода:
#
# Найден e-mail: ya@gmail.com, позиция (122, 134)
# Найден e-mail: papa@mail.ru, позиция (149, 161)
# Найден e-mail: mama@yandex.ru, позиция (164, 178)
# Найден e-mail: brat@hotmail.com, позиция (194, 210)
# Найден e-mail: pushok@rambler.ru, позиция (239, 256)
|
re) | скачать¶1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | import re
# Необходимо найти все телефоны и их описание
page = """http://минобрнауки.рф/контакты
Минобрнауки России. Телефоны для связи.
Справочная служба +7 (495) 539 55 19
Факс +7 (495) 629 08 91
"Горячая линия" +7 (499) 553 09 63
Общественная приемная +7 (499) 236 18 83
Контакты для представителей СМИ +7 (495) 629 92 12
Отдел государственной службы и кадров +7 (495) 629 36 42"""
# 1. re.compile() + regex.finditer() + нумерованная группа
print("1. нумерованные группы")
PHONE_REGEX = r"^(.+?)\s+(\+7 \(\d{3}\) \d{3} \d{2} \d{2})$"
regex = re.compile(PHONE_REGEX, re.MULTILINE)
for match in regex.finditer(page):
name, phone = match.group(1, 2)
print("Наименование: '{}', Телефон: '{}'".format(name, phone))
# 2. re.compile() + regex.finditer() + именованная группа
print("\n2. именованные группы")
PHONE_REGEX = r"^(?P<Наименование>.+?)\s+"\
"(?P<Телефон>\+7 \(\d{3}\) \d{3} \d{2} \d{2})$"
regex = re.compile(PHONE_REGEX, re.MULTILINE)
for match in regex.finditer(page):
name = match.group("Наименование")
phone = match.group("Телефон")
print("Наименование: '{}', Телефон: '{}'".format(name, phone))
# 3. re.compile() + regex.finditer() + regex.groupdict()
print("\n3. regex.groupdict()")
for match in regex.finditer(page): # regex уже был создан во 2-м пункте
# Словарь match.groupdict() содержит все именованные группы
print("Наименование: '{Наименование}', Телефон: '{Телефон}'".
format(**match.groupdict()))
# -------------
# Пример вывода:
#
# Наименование: 'Справочная служба', Телефон: '+7 (495) 539 55 19'
# Наименование: 'Факс', Телефон: '+7 (495) 629 08 91'
# Наименование: '"Горячая линия"', Телефон: '+7 (499) 553 09 63'
# Наименование: 'Общественная приемная', Телефон: '+7 (499) 236 18 83'
# Наименование: 'Контакты для представителей СМИ', Телефон: '+7 (495) 629 92 12'
# Наименование: 'Отдел государственной службы и кадров', Телефон: '+7 (495) 629 36 42'
|
11.1.5. Элементы функционального программирования¶
Функциональный стиль программирования - это подход, когда вычисления программируются путем комбинирования функций, а не последовательностью действий, как в императивном стиле программирования.
Основное преимущество такого подхода к программированию заключается в том, что при его использовании (теоретически) намного проще разрабатывать функции по отдельности и проще отлаживать функциональные программы. Также плюсом является, что функциональные программы не изменяют свое состояние, поэтому вполне возможно рассуждать об их функциях с математической точки зрения.
С функциональным программированием тесно связаны три понятия: отображение, фильтрация и упрощение.
В Python существует несколько функций поддерживающих данные концепции:
map(): отображение;
filter(): фильтрация;
functools.reduce(): упрощение;
lambda;
comprehension (коллекционные включения).
11.1.5.1. Функция map()¶
-
map(function, iterable, ...)¶ Применяет функцию
functionк каждому элементу итерируемого объектаiterableи возвращает результат.Если аргументов
iterableнесколько, процесс продолжается аналогично до минимальной длины всех итерируемых объектов.
Функция map() работает аналогично соответствующему алгоритму с использованием цикла for, но, как правило, выполняется быстрее.
Пример использования функции map() приведен в Листинге 11.1.12.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | import math
# 1. Ввод нескольких чисел в одной строке
a, b, c = map(int, input("Введите 3 числа через пробел: ").split())
print(a, b, c)
# 2. Формируем список квадратов элементов
values = list(range(6))
print(values) # [0, 1, 2, 3, 4, 5]
# 2.1. Стандартный метод с использованием цикла for
squared = []
for x in values:
squared.append(x**2)
print(squared) # [0, 1, 4, 9, 16, 25]
# 2.2. map
squared = list(map(lambda x: x**2, values))
print(squared) # [0, 1, 4, 9, 16, 25]
# 3. Несколько итерируемых объектов в map: получаем список степеней чисел
powers = list(map(math.pow, values, [2, 3, 4]))
print(powers) # [0.0, 1.0, 16.0]
|
11.1.5.2. Функция filter()¶
-
filter(function, iterable)¶ Возвращает копию итерируемого объекта
iterableс элементами, для которых функцияfunctionвозвращаетTrue.
Функция filter() является эквивалентом для спискового включения:
item for item in iterable if function(item), еслиfunctionнеNone;item for item in iterable if item, еслиfunctionявляетсяNone.
filter() работает аналогично соответствующему алгоритму с использованием цикла for, но, как правило, выполняется быстрее.
Пример использования функции filter() приведен в Листинге 11.1.13.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | # Создать список отрицательных чисел из произвольного списка чисел
values = list(range(-10, 11))
# 1.1. Стандартный метод с использованием цикла for
negatives = []
for x in values:
if x < 0:
negatives.append(x)
# 1.2. Списковое включение
negatives_2 = [x for x in values if x < 0]
# 1.3. filter
negatives_3 = list(filter(lambda x: x < 0, values))
print(negatives) # [-10, -9, -8, -7, -6, -5, -4, -3, -2, -1]
print(negatives_2) # [-10, -9, -8, -7, -6, -5, -4, -3, -2, -1]
print(negatives_3) # [-10, -9, -8, -7, -6, -5, -4, -3, -2, -1]
|
11.1.5.3. Функция reduce()¶
-
functools.reduce(function, iterable[, initializer)¶ Применяет функцию
functionс 2-мя аргументами к каждому элементу последовательностиiterableслева направо, аккумулируя и возвращая результат вычисления.Дополнительный параметр
initializer(при наличии) определяет начальное значение результата; если он не задан - используется первый элементiterable.Например:
reduce(lambda res, x: res + x, [1, 2, 3, 4, 5]) # 15
определяет сумму списка, как
((((1+2)+3)+4)+5), где:res- аргумент, накапливающий результат вычисления;x- очередной элемент последовательности.
Пример использования функции reduce() приведен в Листинге 11.1.14.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | import random
import functools
# 1. Сумма и произведение чисел в списке
random.seed(101)
values = list(random.sample(range(-15, 15), 5))
print(values) # [3, 12, -9, 14, 2]
# 1.1. Стандартный for
l_sum = 0
l_mult = 1
for value in values:
l_sum += value
l_mult *= value
# 1.2. reduce
l_sum_2 = functools.reduce(lambda res, y: res + y, values)
l_mult_2 = functools.reduce(lambda res, y: res * y, values)
print(l_sum, l_mult) # 22 -9072
print(l_sum_2, l_mult_2) # 22 -9072
# 2. Формирование строки из списка
strings = "Болтовня ничего не стоит. Покажите мне код. Linus Torvalds".split()
# ["Болтовня", "ничего", "не", "стоит.", "Покажите", "мне", "код.",
# "Linus", "Torvalds"]
print(strings)
# 2.1. Стандартный " ".join()
expr_1 = " ".join(strings)
# 2.2. reduce
expr_2 = functools.reduce(lambda res, y: res + " " + y, strings)
print(expr_1)
print(expr_2)
|
- 1
Sebesta, W.S Concepts of Programming languages. 10E; ISBN 978-0133943023.
- 2
Python - официальный сайт. URL: https://www.python.org/.
- 3
Python - FAQ. URL: https://docs.python.org/3/faq/programming.html.
- 4
Саммерфилд М. Программирование на Python 3. Подробное руководство. — М.: Символ-Плюс, 2009. — 608 с.: ISBN: 978-5-93286-161-5.
- 5
Лучано Рамальо. Python. К вершинам мастерства. — М.: ДМК Пресс , 2016. — 768 с.: ISBN: 978-5-97060-384-0, 978-1-491-94600-8.
- 6
UNIX-время, соответствующее 1 000 000 000 секунд. Дата отмечалась в Копенгагене 9 сентября 2001 г. в 01:46:40. URL: https://upload.wikimedia.org/wikipedia/commons/e/e3/1000000000seconds.jpg.
- 7
Пример, показывающий сброс даты (в 03:14:08 UTC 19 января 2038 года). URL: https://upload.wikimedia.org/wikipedia/commons/e/e9/Year_2038_problem.gif.
- 8
Табло показывает 3 января 1900 года, вместо 3 января 2000 года. Франция. URL: https://upload.wikimedia.org/wikipedia/commons/f/fb/Bug_de_l%27an_2000.jpg.